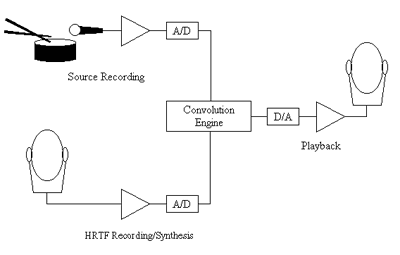
Figure 1.1: An auralization system
INTRODUCTION TO AURALIZATION
1.0 What is Auralization?
1.1 A bit of history
1.2 The current state of the art
1.3 Variables in an auralization system
Until recently, the focus of these efforts was in providing stereoscopic three-dimensional graphics to stimulate our sense of vision. This is understandable, considering the extent to which human perception relies on visual information. We use our eyes as the primary tool for exploring our world, and when presented with contradictory information it is our visual perceptions that take precedence in our mental processing [1].
After much effort by researchers, stereoscopic displays are now available which can provide some degree of representation of a virtual world. However, the early pioneers found that though visual cues are a predominant part of our perceptions, they alone are not sufficient to create believable worlds. Coupling a three-dimensional visual display with conventional stereo sounds presents a very unnatural experience for the user. As a result, the field of auralization - three-dimensional sound - was drawn to the forefront of audio.
There are a number of motivations for developing auralization systems in addition to the advent of virtual reality. True three-dimensional processing adds an auxiliary creative element to be manipulated by the commercial musician or record producer, providing a new realm of entertainment to explore. Auralization also allows end-users to benefit from the "cocktail party" effect, the brain's ability to use localization cues to isolate a single conversation from a multitude of similar sounds. This is very useful in designing systems where a user must monitor several communication channels at once. Applications include air traffic control, NASA mission control, and fighter pilot communications. Virtual audio displays also potentially utilize auralization algorithms, with promise for use in a general office environment as well as applications for the visually impaired.
The newfound importance of this field is evidenced by the recent explosion of auralization publications, both technical and pedestrian. While only a few years ago pioneers in virtual audio had difficulty getting papers published [2], the past few years have seen numerous articles in the Journal of the Audio Engineering Society (JAES) and the Journal of the Acoustical Society of America (JASA), as well as various virtual reality, telepresence, and human factors publications. The October 1993 AES convention in New York was titled "Audio in the Age of Multimedia" and featured numerous workshops and panel discussions on auralization. In addition, the popular press has latched on to the terms "3-D" and "Virtual", producing a plethora of articles on various degrees of auralization processing available to the consumer and semi-professional musician. Unfortunately, many of these systems are more accurately classified as surround sound or enhanced stereo, rather than true auralization systems [3][4][5]. It is in the AES journal's recent special auralization issue [6] that Kleiner proposed a definition for the term at the center of this activity:
"Auralization is the process of rendering audible, by physical or mathematical modeling, the sound field of a source in space, in such a way as to simulate the binaural listening experience at a given position in the modeled space."
Through the years, a variety of means for recording three-dimensional soundfields have been developed. The Ambisonics system [12] attempted to record the three orthogonal velocity vectors and one absolute pressure at a given point in space, thus completely defining the soundfield at that point. A matrix network and equalizers manipulated the four channel direct recording (A-format) to a different four channel form (B-format) which could then be manipulated to produce one of the following: a steerable mono output, a stereo pair whose effective angle, vertical tilt and rotation can be manipulated, or a quadraphonic set of outputs whose effective direction and tilt can be manipulated. While it found some success by providing additional control over a conventional stereo pair in multitrack recording, the need for a four-channel recording medium and specialized playback environment limited the usefulness and commercial viability of this system for general use.
Dummy-head recording has demonstrated great success within the limitations of a two-channel stereo- compatible format which requires no unusual playback apparatus. Microphones in a carefully constructed artificial head record sound from the location of the "eardrums" onto a standard two-track medium for playback through headphones. These systems can provide convincing reconstructions of a number of auditory environments, though results vary based on the accuracy of the artificial ear and the correlation to an individual listener's head and ear shape. They are also limited to playback through headphones. The primary failing of these systems is that they are only capable of recollection, not synthesis. It is not possible for the user to position a pre-recorded sound at an arbitrary position in space; items are locked into their positions as they were recorded.
Wightman and Kistler provided groundbreaking data and validation for free-field simulation over headphones [13][14]. Through extensive experimentation, they recorded the head-related transfer functions (HRTFs) of numerous subjects for an array of sound source locations. The HRTF is one of three cues used by the brain to decipher location information, and is the primary intimation utilized to extract sound source elevation. It is modeled as a filter which accounts for the effect of the reflections off the pinnae (outer ear) and shoulder, as well as the shadowing effect of the head itself. The head-related transfer functions (HRTFs) acquired during their research are still widely used today. Wightman and Kistler's "SDO" HRTF provided a basis for the set utilized in the programs accompanying this research [15].
Begault recently identified a number of challenges to the successful implementation of three- dimensional audio systems [16]. Externalization (distinguishing a source as outside the listener's head) is a problem Begault himself has pursued [17][18]. Often though the listener is able to perceive azimuth and elevation differences, the sound appears to be very close to, or inside, the head. The perception of distance is a difficult illusion to construct. One key to successful externalization is an understanding of the role of room reflections, as noted by Hartmann [19][20]. The human brain utilizes information contained in the first few reflections from a reverberent environment to contribute to a perception of space.
Another obstacle to auralization is user-dependence of the HRTFs. There is a great deal of debate on whether better results are obtained with a "good listener's" HRTF, a "composite average" HRTF, or a "generalized" HRTF such as those developed by Wightman and Kistler [21]. A "good listener" HRTF is the measured HRTF of an individual who exhibits above-average localization ability in free-field conditions. Some listeners actually perform better with such a set than with their own measured HRTF [14]. A "composite average" is simply the HRTFs of many individuals averaged to create a single, representative HRTF. The problem with this approach is that it averages not only the common but the unique filter traits as well. In an effort to extract only the common characteristics across HRTF variation, Wightman and Kistler have performed a principal component analysis of a large number of measured HRTFs, resulting in a small set of basis functions from which HRTFs can be constructed with a high degree of accuracy. Because these functions encompass the shared features, any deviation is a result of the individual's own variation - typically less than 5%. Despite these efforts, the fact remains that HRTF compatibility varies widely in the general population [1].
Currently, most applied research depends on the Convolvotron, developed by Foster and Wenzel at Crystal River Engineering [2]. It is the principal commercial product available for serious auralization work. It combines a control CPU and DSP convolution engine to process audio signals using a library of measured HRTFs. Up to four sources may be auralized at once. A number of smaller auralization products are also under development at CRE, with development goals similar to the goals of this project: to extract more functionality from limited computing resources (constrained primarily by the inter-sample time period) through the application of superior algorithms.
1.3 Variables in an auralization system
In an auralization system, there are many parameters which may affect the listener's perception of the
sound source. In order to address these issues and provide compensation, it is first necessary to identify
them. In its simplest form, an auralization system may be represented as four steps: source recording,
HRTF recording (or synthesis), a convolution means, and a playback system, as shown in Figure 1.1. Each
of these has a set of parameters which must be controlled and defined to achieve accurate results.
Providing a means for tracking and compensating for head movement also contributes to resolution of these reversals. By combining movement and memory of recent stimuli, the listener can "triangulate" to determine the true location of the source. Since motion affects front source interaural differences contrary to rear sources, the direction of change is sufficient to indicate the hemisphere in which the source is located. This method also has the advantage of relying on the fairly robust ITDs and ILDs, rather than the delicate HRTFs, to provide front/back differentiation.
For more discussion of integration with visual displays and head tracking, see Chapter 8.